Address parsing | How to parse an address into components
Address parsing is the process of dividing a street address into individual or grouped components.
Since the word “parse” means to divide something into components, some refer to address parsing as the process of dividing a street address out of or “extracting” an address from a string of text.
A successful address parser requires similar processes and skills regardless of your definition. Whether you're dividing real-world addresses into parts or are extracting address elements out of blocks of text, you'll still be required to identify where the address starts, what components exist, and where the address ends.
We've found that there are multiple ways that people verify and validate addresses.
We find our parsing tools useful, so we've included some links here.
In this article, we’ll cover:
- Video: What is address parsing?
- Uses for parsed addresses
- Typical approaches to address parsing
- How is address parsing used in geocoding?
What is address parsing?
When most people use the phrase “address parsing”, they’re referring to the process of taking an address or a string of text and breaking that address into components, or separate address elements. This is similar to the word "parse” which is to break down words or sentences into parts, syntax, etc. Let’s parse this address:
1 E King St Apt 1 York PA 17401-1448
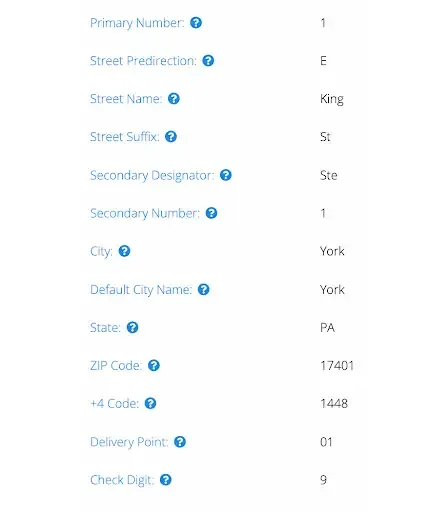
While there are numerous ways address information can be divided, here is a common way the address structure may be parsed:
- Primary number: 1
- Street predirection: E
- Street name: King
- Street suffix: St
- Street postdirection: N/A
- Secondary designator: Ste
- Secondary number: 1
- Extra secondary designator: N/A
- City: York
- State: Pennsylvania
- ZIP Code: 17401
- +4 Code: 1448
As you can see, this address has been parsed (broken down) into the appropriate data sets.
Why parsing is just one step in the process
Parsing is not the only step in the address verification process but it is a beneficial outcome! Getting parsed address data starts with:
- The information of the entered address
- Parsing then takes place and the address is broken down into components and individually identified
- Spelling, casing, and abbreviation information are corrected for the parsed address components
- We return your standardized address along with some beautifully parsed address data
Normalization
Data Normalization is the transformation of data into an accepted, authoritative format. The accepted format is usually determined by a recognized governing body, committee, or authority. Similarly, Address Normalization is the transformation of address data into an accepted format that is determined by a local postal authority. The USPS determines the address format for addresses in the United States.

When address information enters a system there are a couple of variables that may differ. With millions of addresses in the US, and billions of addresses worldwide, endless combinations are possible. Let’s use the address we already parsed. Addresses can have minor deviations and still function for mail delivery:
- 1 E King St apartment 1 York PA 17401
- 1 E king St Apt 1 York PA 17401
- 1 E King Street Apt 1 York PA 17401
A valid address can be entered multiple ways. Delivery point information may contain differing abbreviations, misspellings, casing, or in the case of alias locations, may appear entirely different. These address ambiguities show the importance of normalization. All of these inputs are technically correct, but normalization and standardization would take these duplicate addresses and return the single authoritative address:
- 1 E King St Apt 1 York PA 17401
Uses for parsed addresses
While parsed address data may be a fraction within the address verification and geocoding process, the information given has many uses. Address parsing enables:
- Better addresses matching across datasets
- The creation of persistent unique identifiers
- More precise location data analysis
- How many customer addresses in a city contain secondary address information such as sub-units, apartments, or suites? More accurate information ensures that the information is utilizable.
- Takes unstructured data, and converts that information into usable information.
- Better address management as well as better address storage
- Allows for normalization or standardization
- It can be used for de-duplication of redundant addresses within a system
- It can be used for companies to store addresses in their component form meaning that instead of storing the address, they store the parsed address information
Typical approaches to address parsing
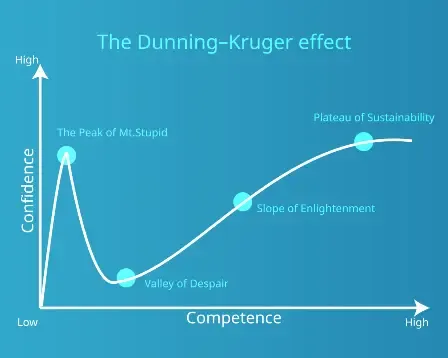
When a developer thinks about parsing and standardizing real-world addresses, they inevitably think that regular expressions (Regex) are the answer. This can lead to the Dunning-Kruger effect, which simply means that you overestimate your ability to do something, especially when compared to capable counterparts. The Dunning-Kruger effect is common, but addresses are not regular. So, no matter how complex your regex is, it will miss out on the thousands of edge cases found in address data.
Street addresses also vary in formatting from one area to another, so even if you work out most of the edge cases for parsing with regular expression and it works well enough in one area, it may still choke on addresses the next town over.
There are 2 approaches when it comes to address parsing.
- Request the address from your user or customer as components with a different field for each value. That way, you don’t have to parse, since the user did it for you. It’s not the best user experience creates more consistent address data.
- Request the address string in a freeform style, or free-form address strings, meaning the address is entered as a whole within one line.
Requesting the address string as freeform text creates more possible differences with the same address as there is nothing that controls for uniform entry. One user may enter the apartment number first while another may enter it after the street. Parsing an address can be done on different levels depending on what detail you need.
Generally, when you parse an address string, the returned information would be grouped into these typical 10 categories:
- Primary
- Pre-direction
- Street name
- Street suffix
- Post-direction
- Secondary designator
- Secondary number
- City
- State
- ZIP Code
Parse an address into Firstline (the first 7 components) and Lastline (the last 3 components).

Using regex parsing for an address on different levels is not feasible because there are too many components that can be mistaken for other components. Here is a real address example:
102 W E ST ELKTON, VA 22827
The question becomes:
- What is the W? It could be a pre-direction, or it could be a street name.
- What is the E? It could be a street name or a post-direction to W street.
- What is ST? It could be a street suffix or part of the city name.
Another thing to consider is addresses that do not fit the typical format, such as:
PO BOX 123 LOGAN, UT 84321 HC 13 BOX 438 SNELLVILLE, GA 30078 64 UNIT 4350 DPO, AE 09977
Also, what if the customer doesn't respect the standard accepted order of components, misspells a directional (North, East, South, West), or places a secondary value before the primary, etc.? There are simply too many ways to mess up an address, and too many ambiguous cases for a regex expression to work or be effective.
Using regex to parse Firstline addresses could be possible in a majority of the cases, but is still not accurate enough to be reliable. For example:
1106 SW EAST LOUISE CIR PORT SAINT LUCIE, FL 34953

- Is PORT a secondary designator or part of the city name?
- Is SAINT a secondary number or part of the city name?
In an ideal world, city and state names would only be a single word, then perhaps a regex could work. But as it stands, it isn't an ideal world, and there are too many ways for a regex to make the wrong decision or report an error when given vague or incorrect information. Even if the regex knew all city names for all states, once a customer spells something wrong, the regex would fail.
Just for fun, we have included a reference to compare how difficult regex can be. This is a regex that validates an email address. Hang onto this; it may save someone’s life. Email addresses must fit a specific format, so this regex is simple and hard to mess up. Just imagine a regex or series of regex statements to parse something as complex and error-prone as an address. No thanks!
^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$
How is address parsing used in geocoding?
The first step needed before geocoding should take place is to clean, and standardize the address data. Clean data is important and can make a world of difference in the time and energy consumed verifying information.
As mentioned above parsing can play many important roles and in this specific case, the normalization or standardization, as well as the deduplication of redundant addresses plays a key role. Essentially we need to know we're working with valid addresses in order to know that we have the right addresses.
Once the address has been parsed, standardization can take place. After normalization and standardization, geocoding and address verification can take place.
Conclusion
While address parsing is a small step within address verification and geolocation, it’s essential.
It helps clear up redundant addresses across datasets, it can also help create unique identifiers, be used to make helpful data analysis filters, make for better address management, allow for address standardization, and can help to clean data as well as de-duplication.
Was this helpful?

