

Location truth: The foundation of insurance risk assessment for weather and crime

An insurance risk assessment is what insurance and reinsurance companies perform to assess the financial impact and likelihood of future claims on their balance sheet at the time of claim submission and when assessing whether to take on new policyholders.
Key aspects of insurance risk management are:
- The process: Risk identification (damage, liability), assessing their probability of occurrence and level of severity, and assigning appropriate coverage amounts to align premiums with actual risk levels and ensure insurer solvency.
- The factors: Geographically-related (historical natural disaster patterns, fire risk and weather patterns, proximity to risks like fault lines or bodies of water, etc.) and property descriptors and metadata (age of structures, roof types, elevation, past loss history, claims history, crime rates, etc.).
- The methods: Accurate address data backing statistical models, data analytics tools, AI, and risk quantification techniques, to appropriately set premiums and calculate coverage.
Smarty provides the best foundation for your property risk management. Backing your assessment with geocoded structure rooftops, understanding the actual parcel boundaries, and seeing over 350 property data points? Yes please. You can test them out live and for free below, or continue reading to learn more about how location truths impact insurance risk assessments (and your bottom line and financial stability!).
Here’s what you can expect to learn about regarding insurance risk assessments:
- What is location truth for insurance risk assessments
- Insurance risk assessment vs. property risk assessment in insurance: What’s the difference?
- How risk management works specifically in property & casualty insurance
- How insurers typically conduct an insurance risk assessment
- How insurance risk assessment and property risk management connect (and why it matters)
- The core building blocks of insurance risk assessment and mitigation plans
- The hidden cost of “good enough” data
- Tools that support data collection and scenario analysis for property risk management
- Implementation tips: Improving your assessment and risk mitigation plan without boiling the ocean
- Conclusion: Turning risk discipline into better underwriting outcomes
- Insurance risk assessment FAQs
What is location truth for insurance risk assessments
You can’t out-model bad location inputs.
For many property and casualty (P&C insurance) carriers, the highest-return improvement available right now isn’t another modeling layer. It's better location data.
Insurance companies have spent years improving models, adding third-party data, and modernizing underwriting workflows. But one foundational weakness still undermines a surprising amount of risk work: uncertain location inputs.
If the insured location is wrong, approximate, duplicated, or inconsistently represented across systems, then climate risk assessment, flood risk, wildfire risk, crime risk, aggregation analysis, cyber risk assessment, and claims management workflows all inherit that uncertainty.
That raises an important question: what makes a location’s information verifiably true?
Location truth begins when guesswork and approximation are replaced with verifiable facts. In the insurance sector, that means working from a location record built on trustworthy, standardized, and resolvable data, including:
- A standardized, verified address tied to the property
- Parcel boundaries that define the land being evaluated
- Rooftop- or unit-level geocodes for the relevant structures on that parcel
- Historical weather, crime, and disaster patterns tied to that exact location
- Property data points that add context about the asset itself, including structural characteristics and building attributes that influence vulnerability and loss potential
When those foundational address, parcel, geocode, hazard, and property details are missing, incomplete, or loosely inferred, the insurer is no longer assessing risk with full confidence. It's assessing the property risk score through approximation.
That approximation can distort underwriting and pricing decisions, weaken risk governance and capital planning, and create regulatory exposure. This can be incredibly frustrating and expensive when insurers remain responsible for fair, defensible, and compliant rating and underwriting practices.
Insurance risk assessment vs. property risk assessment in insurance: What’s the difference?
Insurance risk assessment is the broader discipline insurers use to evaluate the likelihood and severity of future losses, enabling them to make decisions on underwriting, pricing, portfolio mix, capital, and operations. In regulatory terms, that broader discipline sits within enterprise risk management frameworks.
Property risk assessment is narrower and more location-dependent. It focuses on the physical asset, the land it occupies, the hazards surrounding it, and the conditions that make loss more or less likely. A property insurer is asking more than whether a risk exists in theory. It's asking what is true about this exact property, at this exact location, under these exact conditions.
That distinction matters because insurance risk assessment is the broader business discipline, while a property risk assessment is one of its most location-sensitive inputs.
Both appear throughout the insurance lifecycle, from underwriting and pricing to servicing and claims, as well as cyber risk assessment.
How risk management works specifically in property & casualty insurance
Risk is exposure to loss that must be identified, measured, priced, monitored, and managed.
Sounds simple, but the operating reality is more demanding.
Insurers are balancing catastrophe exposure, inflationary pressure, changing weather patterns, market competition, fraud, cyber threats, digital vulnerabilities, regulatory expectations, and customer retention at the same time.
And property risk management is a shared responsibility across multiple teams:
- Chief Underwriting Officers and underwriting management teams use property risk scoring processes to guide carrier appetite, referrals, pricing strategy, inspections, and terms.
- Data science managers and analytics leaders use them to build, test, and refine the features and models that support decision-making.
- Catastrophe modeling leaders use them to understand concentration, accumulation, and probable loss under event scenarios.
- CIOs and CTOs use them to determine whether the data pipeline is reliable enough to support all of the above.
The benefit to insurers is better model output, which has major ripple effects on decision quality within a decision-making framework. Better location inputs can reduce misclassification, improve segmentation, support more defensible pricing, and reduce avoidable operational friction.
The benefit to policyholders is also meaningful and worth noting here.
More precise location and property data can support fairer assessments, fewer unnecessary delays, and more consistent decisions across quoting, underwriting, renewal, and claims.
How insurers typically conduct an insurance risk assessment

1. Define the exposure
The insurer establishes what risk it’s being asked to assume and where that risk sits.
2. Assess the loss potential
The carrier evaluates hazard, vulnerability, and exposure using underwriting data, property characteristics, location intelligence, and analytics.
3. Align decision-makers
Underwriting leaders shape appetite, pricing, referrals, inspections, and terms.
Analytics teams support those decisions with models and features.
Catastrophe teams evaluate concentration and event loss potential.
Technology leaders ensure the data infrastructure can consistently support all of it.
4. Act on the findings
The insurer uses that assessment to make underwriting, pricing, portfolio, and operational decisions with greater confidence and meticulous precision.
5. Strengthen business outcomes
Done well, property risk scoring improves decision quality. It also supports more defensible pricing, reduces operational friction, and creates a more consistent and transparent experience for policyholders. This later pays off by boosting customer experience scores and brand loyalty as much as your bottom line.
How insurance risk assessment and property risk management connect (and why it matters)
Insurance risk assessment identifies the ingredients.
Insurance risk management decides what goes on the plate.
Assessment is how the insurer determines what risk is actually present. Management is what the insurer does with that information.
That may mean adjusting terms, changing price, ordering an inspection, limiting capacity in a concentration zone, recommending mitigation, applying risk control methods, or declining the risk altogether. And, we recommend that you perform both processes frequently. The NAIC’s ERM and ORSA Guidance Manual reinforces that this isn’t a one-time scoring exercise, but stresses that it’s an ongoing management discipline.
It’s where location truth becomes strategic.
If the underlying location is only approximately understood, the insurer is making decisions based on compromised and contaminated ingredients. A carrier may believe it has assessed the risk precisely when it has really modeled an approximation with confidence.
That’s the hidden cost of “good enough” location inputs. They create a false sense of certainty and can make a carrier feel more data-driven without actually improving accuracy.

The core building blocks of insurance risk assessment and mitigation plans
Every risk evaluation is built from foundational components.
Exposure answers the questions “what is at stake?” and “where is it located?”. This includes insured value, replacement cost, business dependence, and portfolio concentration. In the insurance sector, exposure is inseparable from place.
Hazard answers the question “What could happen at this location?” Floods, wildfires, hail, wind, freezes, theft, and other loss drivers are not evenly distributed and vary by geography, built environment, and surrounding conditions.
Vulnerability answers the question “How is the asset likely to perform if a hazard occurs?” Quality property data becomes indispensable at this stage. Roof type, year built, square footage, construction class, lot context, and other building- or parcel-level factors help determine whether a property is likely to withstand an event or suffer outsized damage.
Controls and mitigation answer the questions of “Are there factors that reduce the likelihood or severity of risk?” and “What risk control methods are in place?”These may include protective devices, maintenance quality, defensible space, prior repairs, underwriting restrictions, or policy conditions as risk control measures.
Sure, address verification and geocoding tell the insurer where the property is, but property data helps explain the actual risk at that location.
It’s also why US Property Data matters in this discussion. It comes down to improving an insurer’s ability to understand the risk's structure, context, and vulnerability at that specific location.

The hidden cost of “good enough” data
The insurance sector often talks about bad data as an efficiency problem. And they’re not wrong, but as this article hopefully highlights, being only partially right is part of the problem.
Bad location inputs create rework, duplicate records, manual review, inspection waste, and friction between systems. But in insurance, the bigger issue equates to more than administrative inconvenience.
The costs eating into your revenue can also come from false confidence.
An approximately resolved location can still flow through the workflow as if it were precise.
- It can still be scored.
- It can still be priced.
- It can still be included in:
- CAT rollups
- Crime assessments
- Renewal decisions
That’s what makes this data quality problem expensive.
It'll never announce itself as an obvious error.
Instead, it quietly weakens segmentation, introduces noise into analytics, reduces consistency across functions, and makes it harder to defend the “why” behind a decision.
Tools that support data collection and scenario analysis for property risk management
There are many tools that the insurance sector is using to ensure location truths in insurance risk assessments, but the ones most directly tied to building the strongest foundation are address verification, address geocoding, and address enrichment intelligence within a risk management platform.
Address verification’s role in insurance risk assessments
If nothing else, the easiest tool to start with (and one that many insurers are already familiar with and using) is address verification.
Address verification helps insurers confirm that a submitted address is real, standardized, and usable. It checks the address against an authoritative database or dataset, standardizes address components, and can help flag suspicious entries, incomplete records, or potential duplicates for manual review.
This matters because every other step in the property risk assessment process depends on getting the address right first. If the submitted address is invalid, inconsistently formatted, or tied to the wrong property record, then every downstream workflow inherits that uncertainty.
Address verification does not solve every location problem on its own. But it is the first step in replacing messy submissions and inconsistent data entry with something more trustworthy.
Address geocoding’s role in insurance risk assessments
The next most important tool in your insurance risk assessment toolkit is address geocoding.
More specifically, it should be rooftop- or even unit-level accurate. For a foundational truth about a property to be possible, insurers need to understand the finite details surrounding the exact structure being insured.
Without doing extensive investigative work on their own or relying only on insured submissions, carriers should be able to tell whether an apartment complex they’re insuring has 250 units or 25. It should be simple to see whether a farmhouse sits 10 feet or 10 acres from a river, or whether a business they are evaluating is on the ground floor or 45 stories high.
That level of precision matters because hazards don’t operate at the ZIP Code level. Flood, wildfire, crime, and catastrophe exposure can shift dramatically over short distances. Geocoding helps carriers move from a general idea of place to a more exact understanding of location.
Address enrichment’s role in insurance risk assessments
Once an insurer has verified the address and accurately geocoded it, the next step is making that location more useful. That’s where address enrichment becomes essential.
Address enrichment adds the surrounding facts that help insurers understand not just where a property is, but what kind of risk is actually sitting there. That can include parcel boundaries, property attributes, structural characteristics, occupancy context, and nearby environmental or geographic conditions that influence vulnerability and loss potential.
This matters because location alone is only part of the story. Two properties can sit on the same street and still create very different property risk profiles:
- Age
- Size
- Proximity to historical hazard boundaries
- Build materials
- Parcel positioning
These all change an address or location’s exposure, sometimes exponentially. Address enrichment helps carriers move from broad geographic assumptions to a more grounded understanding of the individual property.
PSST. Hey, while you’re here, why not take US Property Data for a spin?
Implementation tips: Improving your assessment and risk mitigation plan without boiling the ocean
This can sound like a massive undertaking, but it does not have to be.
Most insurers do not need to rebuild every workflow, replace every provider, or solve every location-data problem all at once.
The more practical path is to improve the foundation in stages, starting with the tools and workflows that have the greatest downstream impact on underwriting, pricing, catastrophe modeling, and claims.
Start by assessing your insurance cascade
Many insurers already use multiple address data providers in a cascade. That structure exists for a reason. One provider may identify an address as invalid while another can validate it against a different authoritative dataset. One may return only broad geocoding precision, while another can resolve the location to the rooftop or unit level. One may offer limited context around the property, while another may add hundreds of useful property data points.
Over time, that cascading approach can reduce exceptions and improve match rates by sending only unresolved or lower-confidence records farther down the chain. But it also means the providers at the top of the cascade matter most. They have the greatest influence on speed, confidence, cost, and the overall quality of the location record flowing into downstream systems.
Determine which providers focus on refining locational truths at the core level

When comparing address intelligence providers, three evaluation criteria matter most for your insurance risk assessments to be built on locational truths.
- Accurate: How confident is the provider in the precision of its outputs? Can it verify and resolve an address at the ZIP Code level, the street level, the rooftop, or even the apartment or suite level? The stronger the precision, the stronger the foundation for downstream property risk management.
You’ll want a provider who can verify at granular levels with incredible confidence. - Easy to implement/use: How quickly can P&C insurance professionals get up and running, and how efficiently can the solution operate at scale? Time matters, but so does maintainability. A provider should be fast to integrate, straightforward to manage, and capable of processing large volumes of address data without introducing friction (Seriously, it shouldn’t take longer than a matter of hours to run millions of addresses).
You’ll want a provider who is easy and quick to install but handles large volumes of address data at operational scale in breakneck speeds with minimal to no extra effort on your end. - Supportive: What happens when your team has questions, bumps up against edge cases, encounters billing issues, or needs help interpreting results? Strong documentation matters, but so does access to knowledgeable human support. When a provider becomes part of a critical underwriting or risk workflow, responsiveness and the type of support matter.
You should expect responsive, knowledgeable, and human support when the workflow is business-critical.
Reorder your cascade
You don’t need to fire or rip out any existing providers if you don’t want to.
The good news is that P&C insurance professionals do not need a perfect end-state on day one to make meaningful progress. They just need to start where location truth matters most, strengthen the foundation there, and choose to shift partners who will make the work simpler rather than more complex to the top of their cascade.
In many cases, a few targeted improvements at the top of the workflow can create outsized gains in confidence, efficiency, and decision quality without forcing the organization to boil the ocean.
Conclusion: Turning risk discipline into better underwriting outcomes
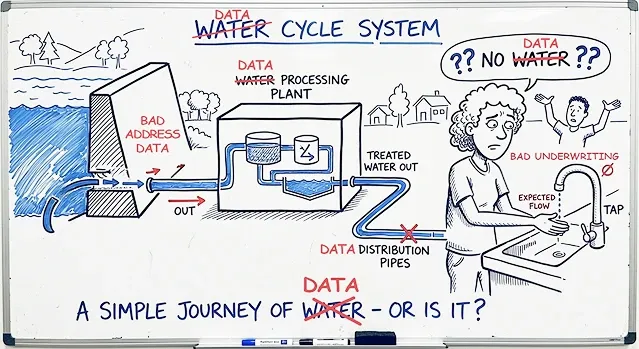
Insurance companies have invested heavily in models, analytics, and third-party data. But no amount of downstream sophistication can fully compensate for weak location inputs upstream.
That’s why location truth matters in insurance risk assessments.
Underwriting, analytics, catastrophe modeling, and claims teams need a more trustworthy foundation for the decisions they make every day.
When the address is verified, the parcel is understood, the structure is accurately geocoded, and the property is enriched with meaningful context, insurers are better positioned to assess property risk with confidence instead of approximation.
For carriers that use an address data cascade, the top slot matters most. The provider at the top of that cascade has the greatest influence on match quality, confidence, speed, exception volume, and downstream cost. A stronger first pass means fewer records sent to fallback providers, fewer manual reviews, less operational friction, and more trust in the location record flowing into the rest of the insurance workflow.
That is what makes Smarty such a strong fit for the top of your cascade.
Smarty helps insurers establish location truth early by combining verified address data, rooftop geocoding, parcel intelligence, and 350+ property data points into a stronger upstream foundation. Instead of relying on approximation and hoping later tools correct the gaps, carriers can start with more precise, more usable, and more decision-ready location intelligence from the beginning.
And in the insurance sector, better beginnings compound.
If the goal is to improve underwriting confidence, reduce avoidable friction, and make downstream models more trustworthy, the highest-return move may not be another scoring layer.
It may be putting a better provider at the top of the cascade.
Insurance risk assessment FAQs
What is an insurance risk assessment?
Insurance risk assessment is the process insurers use to evaluate the likelihood and severity of future losses so they can make decisions about underwriting, pricing, coverage, and portfolio management.

What is the correlation between risk management and risk assessment?
Risk assessment identifies and evaluates the risk. Risk management determines how the P&C insurance company responds to it through pricing, underwriting decisions, risk mitigation plans, and portfolio controls.
How do you perform risk assessment in the insurance sector?
Insurers define the exposure, verify and analyze the property and location, evaluate hazard, vulnerability, and exposure, and then use those findings to guide underwriting and pricing decisions.
What are the 4 types of risk assessment?
In this context, the four core components are:
- Exposure assessment
- Hazard assessment
- Vulnerability assessment
- Controls or mitigation assessment
What are the 5 things a risk assessment should include?
A strong risk assessment should include:
- Verified location
- Relevant hazards
- Property characteristics
- Exposure or insured value
- Any controls or mitigation factors that may reduce the likelihood of loss or its severity
Was this helpful?